Update Apr 21, 2019
Our paper on a stronger, transferable version of this attack has been accepted at ICML!
TL;DR
Our work explores a broad class of adversarial poisoning attacks on neural nets, which we dub “clean-label” poisoning attacks. We present an optimization-based method for crafting poisons. Our results show that neural nets are quite vulnerable to such attacks, heralding the need for data provenance measures.
Attacks on machine learning models
Evasion attacks
While neural networks are robust classifiers of images, speech, and text, being able to learn complex invariances (such as pose, lightning), it turns out they are not robust to visually imperceptible adversarial perturbations. The figure below illustrates the common evasion attack. A perturbation is added to the image of a plane to cause it to be labeled by the otherwise-accurate network as a frog. Evasion attacks are “test time” attacks, because the attacks applies the perturbation during test time.

Poison attacks
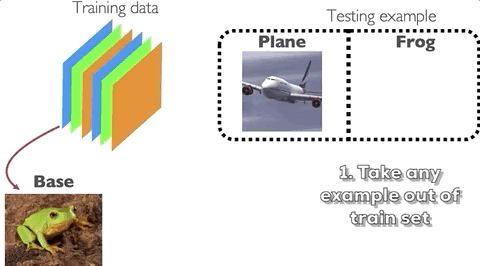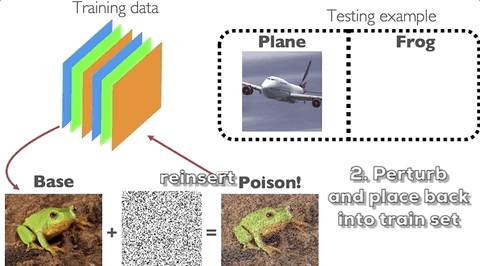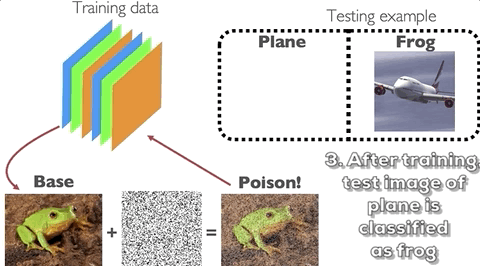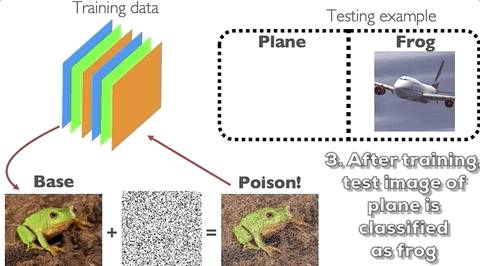
On the other hand, data poisoning is an attack wherein the attacker perturbs examples in the training set to manipulate the behavior of the model at test time. One example of this is the clean-label poisoning attack, illustrated in the figure below. An attacker takes a base example from the training set (or from his own data sources) from the class of, say, frogs. She then applies a perturbation onto that example but does not change the label and reinserts the example back into the training set. The model is then trained by the defender. During test time, when the model sees a particular target image from the class of, say, planes, it will classify it as a frog.
How does data poisoning happen in practice?
How does an attacker gain control over the training data? There are several possibilities
- Scraping from web: If the model builder’s training data acquisition process involves scraping images/examples from the web, then he may be inadvertently picking up poisoned data
- Harvesting inputs: Often acquiring data involves directly harvesting inputs, for example through a honeypot for spam. Poisons could be entered into the training set simply by leaving them on the web and waiting for them to be scraped by a data collection bot.
- Bad actors: Bad actors or rogue agents of the model building organization may manually insert perturbed data into the training set. For example, an insider could add a seemingly innocuous image (that is properly labeled) to a training set for a face recognition engine, and control the identity of a chosen person (such as a co-conspirator) at test time.
Dangers of clean-label poisoning attacks
Clean-label poisoning attacks have a couple aspects that makes them more dangerous than traditional denial-of-service poisoning attacks.
- Being clean-label, the attacks don’t require the attacker to have any control over the labeling of training data. A perturbed frog still looks like a frog and remains labeled as a frog, ensuring that the poison makes it through human audits of the training set.
- The attacks are targeted, changing behavior of the classifier on a specific test instance without degrading overall classifier performance, ensuring that the attack will not be detected by any system performance statistics.
Crafting the adversarial perturbation
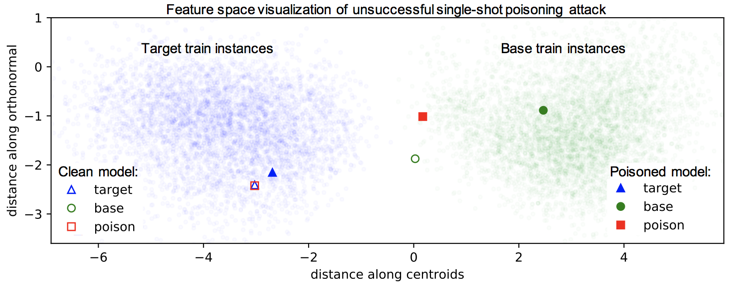
Suppose we want to apply a perturbation ${\bf \delta}$ to a training base image $\textbf{b}$ such that the trained classifier is most likely to misclassify the target image $\textbf{t}$ at test time. While the attacker cannot directly control the model during training, she can optimize the perturbation such that the poison image collides with the target image in feature space. Here we casually refer to feature space as the high level semantic embedding space at the penultimate layer of the network. The intuition is that when the classifier is trained on the poison, the classifier is forced to include the poison on the base side of the decision boundary. If the poison is close enough to the target in feature space, then the decision boundary will inadvertently loop the target into the base side as well. This process is illustrated below.
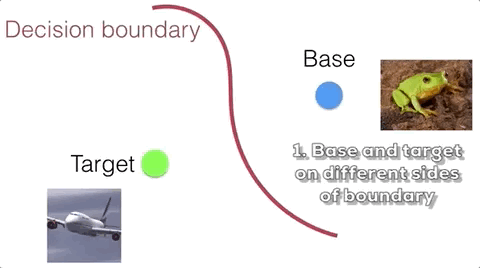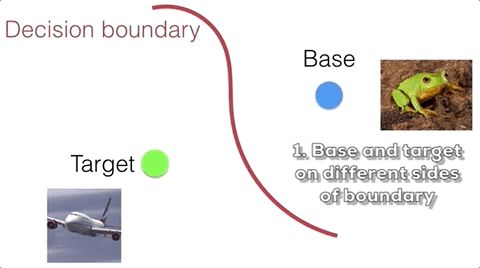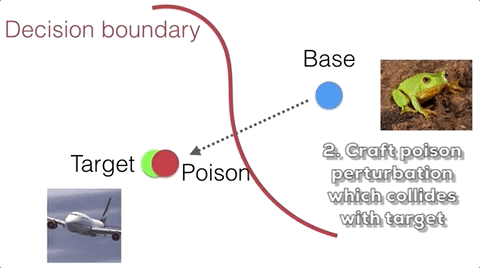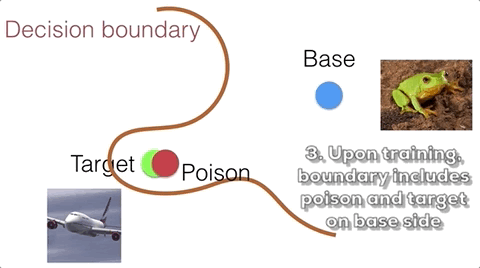
Crafting a feature collision as described above involves optimizing for the following metric
$$ \underset{\delta}{\mathrm{argmin}} \left\lVert f(\textbf{x}) - f(\textbf{t}) \right\rVert^2 + \beta \left\lVert \delta \right\rVert^2 $$
Here the function $f(\textbf{x})$ propagates an input space image to feature space. The first term minimizes the feature space distance, while the second term minimizes the amount of perturbation. The relative importance is parametrized by $\beta$.
Results
We consider attacks in two training contexts: transfer learning and end-to-end training, as shown below. In transfer learning, the feature extractor layers weights are frozen and only the final layer (the classifier) is trained. The feature extractor weights can be pretrained or downloaded. In the end-to-end training context, all the weights are retrained after inserting the poison.

Transfer learning
Transfer learning is often used in industry or medical settings where few data points are available. In the context of transfer learning, we manage to achieve 100% poison success rate across all choices of the target image. We did our experiments on binary classification of two ImageNet classes (dog and fish). If we choose a fish image to be the target, then perturbing any one choice from the dog class would succeed in poisoning the fish. It works the opposite way too when dog is the target and fish is the base. We used an InceptionV3 classification network with pretrained weights downloaded online. The figure below show our one-shot kill results.

Not only are all the target images classified wrongly, but they are misclassified with high confidence. As a control, in the case without poisoning, all the target images have 0% confidence in the wrong class.
End-to-end training
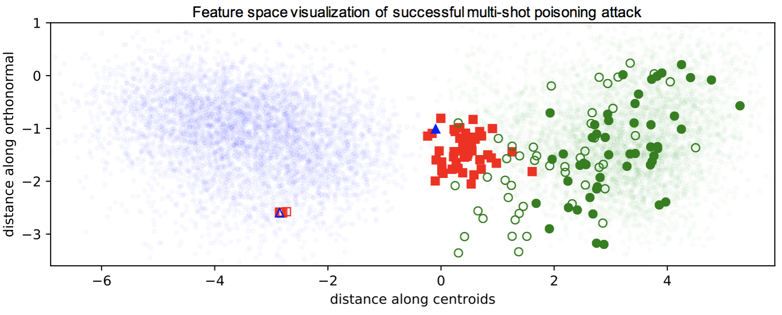
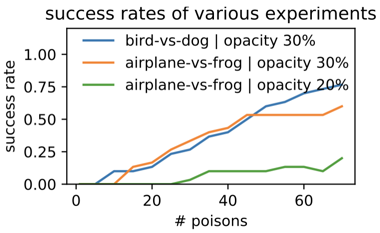
When the model builder does not freeze the any weights of a neural network and trains on the poisoned dataset, i.e. end-to-end training, it is still possible to poison the dataset if multiple poisons are used along with a watermarking trick.
Let’s first see what happens when we attack with a single poison as we did in the context of transfer learning.